Talks ∋ Re-interpreting data ∋ LRUG January 2020
Re-interpreting data

Hi, I’m Murray, I work at Cleo AI and this is a talk about re-interpreting data. We’ll find out what that means shortly.
My downloads

Here’s a screenshot of some of the files in my downloads folder.
The bit after the . in a file name tells the computer what the file is. For example, a .ics is a calendar invite, a .rtf is some kind of rich text document, a .mp4 is a video file, and so on.
Your OS will probably use a handy icon based on the file extension to give you a better hint of kind of thing is in the file, and this icon often indicates which application will open the file if you double click it.
Renaming a file extension
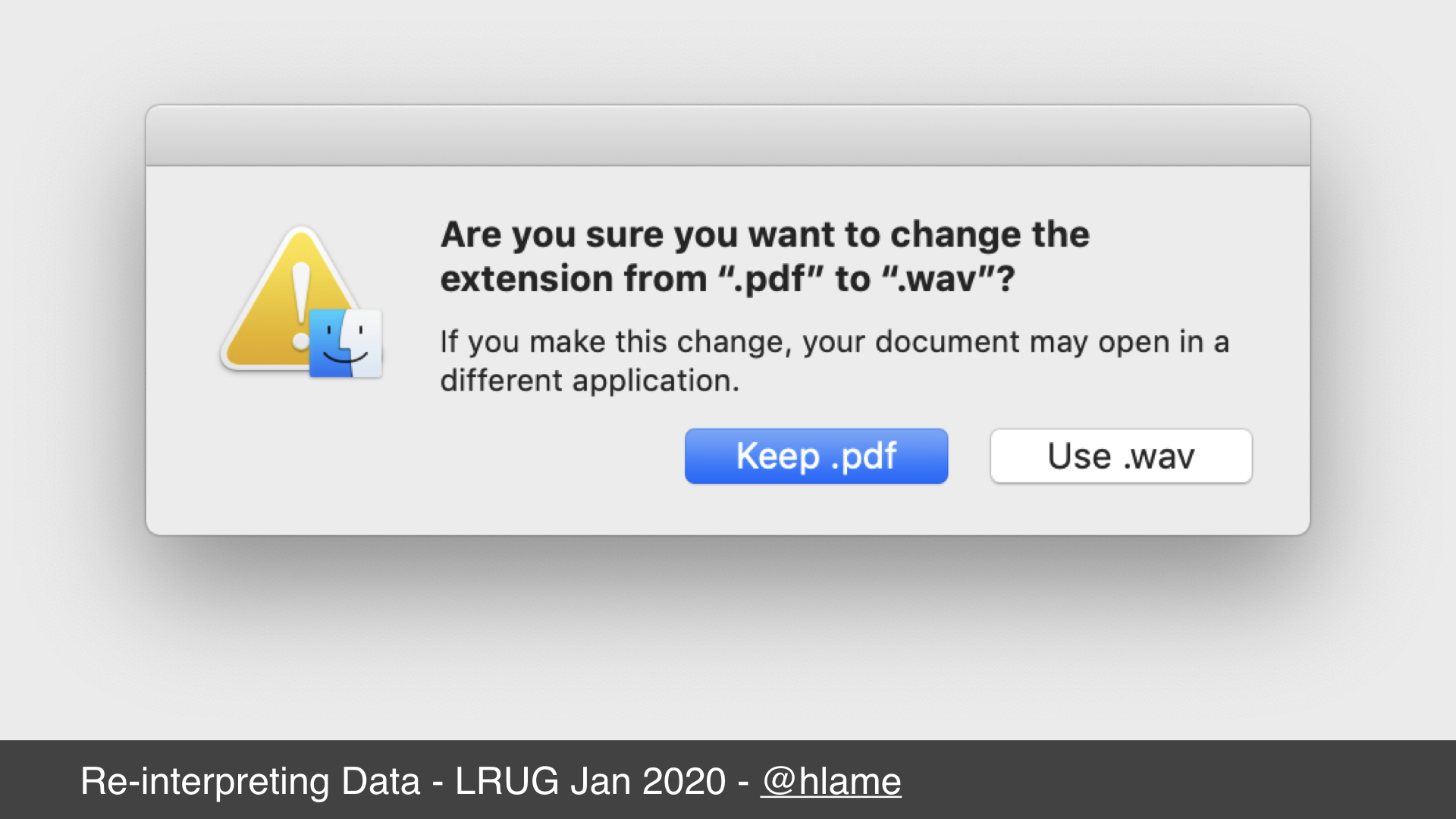
If you rename the file, this’ll change the icon and what application will open it, so your OS will probably warn you.
When I first started using computers, I thought this was all that was involved. Someone gave me a Word document (.doc) and I didn’t have Word at home, so I tried renaming the file to .txt or .rtf to open it in programs I did have. Needless to say this didn’t have the desired effect, I couldn’t read the contents of the file.
The file command

On unix systems there’s a command called file that when run on a file will do its best to tell you what that file actually is. For example, if you type $ file "tax return.pdf" it’ll reply with something like tax return.pdf: PDF document, version 1.3.
This doesn’t seem that useful, because we can tell that tax return.pdf is a PDF because of the .pdf, can’t we?
Well, not really. What if we’d renamed tax return.pdf to tax return.wav? Well file won’t tell us it’s a RIFF (little-endian) data, WAVE audio like it would for a real WAV file, it’ll still say PDF document. How?
How file does what it does

Well, if we read the man page a bit more closely we can see that one of the things the file command does is open the data file and look at some of it to take a guess as to what the contents of it are. It doesn’t just take the name of the file on blind faith and say that a file with extension .pdf actually contains a PDF. If the file is really a WAV, the file command will tell us so, regardless of the file name because file uses the data in the file itself.
Why renaming doesn’t work
Going back to my youthful attempts to open files without the relevant (usually expensive) software, we can now understand why it didn’t work. You can call your file whatever you want, and the OS may use that file name to change the icon and tell you what application will open the file, but that isn’t really important. It’s the 1s and 0s inside the file that really matter. No matter how many times you try, simply renaming a PDF file to a WAV file won’t let you listen to the contents of that PDF file.
The WAV file specification

However…
At some point in my early web-browsing life I came across a website that described the data structure for WAV files.
For those who don’t know, WAV files are simple, uncompressed sound files. The specification explains how to store 1s and 0s so they can be interpreted as sound waves.
Header + Data

Turns out, WAV files are very simple. They’re made up of a header part, and a data part. The header part is split in two.
- The first part tells the world “Hi, I’m a WAV file and I’m this long”. It’s very short and is there to tell other software “if you don’t know what a WAV file is, you can stop now”
- The second part tells the audio software how to interpret the data part. Details in here describe things like: how many channels the sound has (mono, stereo, etc); how many samples there are per second for the sound; how many bits there are per sample. This basically says how detailed the data is - more channels of audio, more samples per second, and more bits per sample means a better digital representation of the analogue sound wave.
The data part is raw 1s and 0s that using the info from the header data, audio software can interpret and output to your speakers.
Could renaming work?
Ok. So. We can’t rename a file from foo.pdf to foo.wav and expect to be able to listen to it.
But, given how simple the WAV file format is, could we take the raw 1s and 0s that make up a PDF file, and put a WAV file header on top of it? Then could we listen to it?
How to create the data part

Yes. But how?
Well, a wav file is header + data. The data part is easy, just copy the 1s and 0s exactly from our source file into our new target file.
How to create the header part

The header is more complicated, but not by much. We can calculate what we need in the header just by looking at the size of our source file and making some choices beforehand about the sample rate and bits per sample before we go in.
Creating the header in ruby
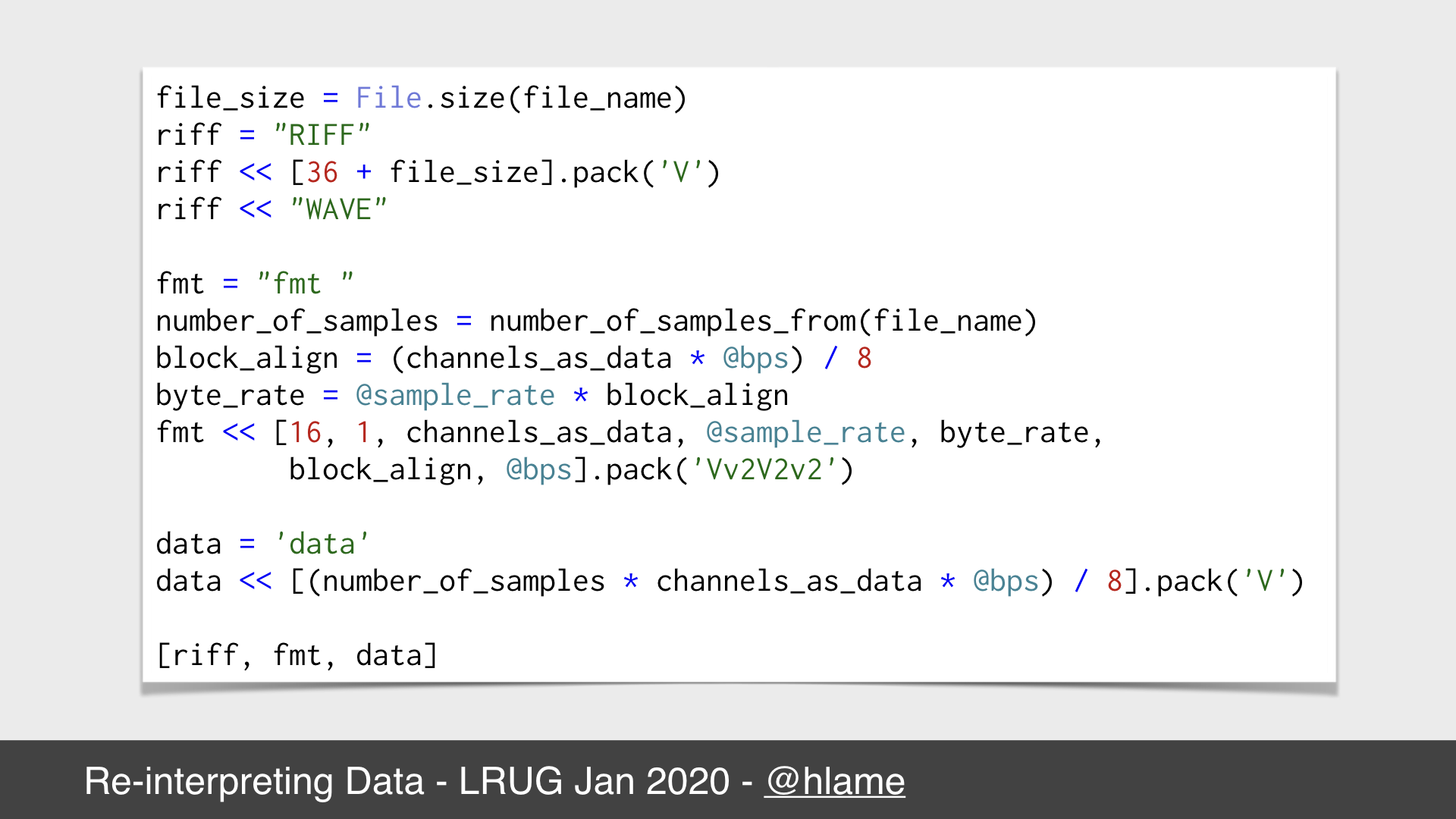
Here’s some ruby code that constructs that header.
The 1st stanza constructs the first part of the WAV header - effectively “I’m a WAV file, and I’m this big, including the size of the header”
The 2nd stanza constructs the second part of the WAV header and includes all the calculated details, you can see all we use is some instance variables (e.g. our choices for what the sample rate and bits per sample will be) and the file size.
The 3rd stanza constructs the start of the data part of the WAV file.
What’s missing is then code to write this to a file, and copy the data from the source file. You can probably all imagine that, so I’ve elided it.
Using Array#pack
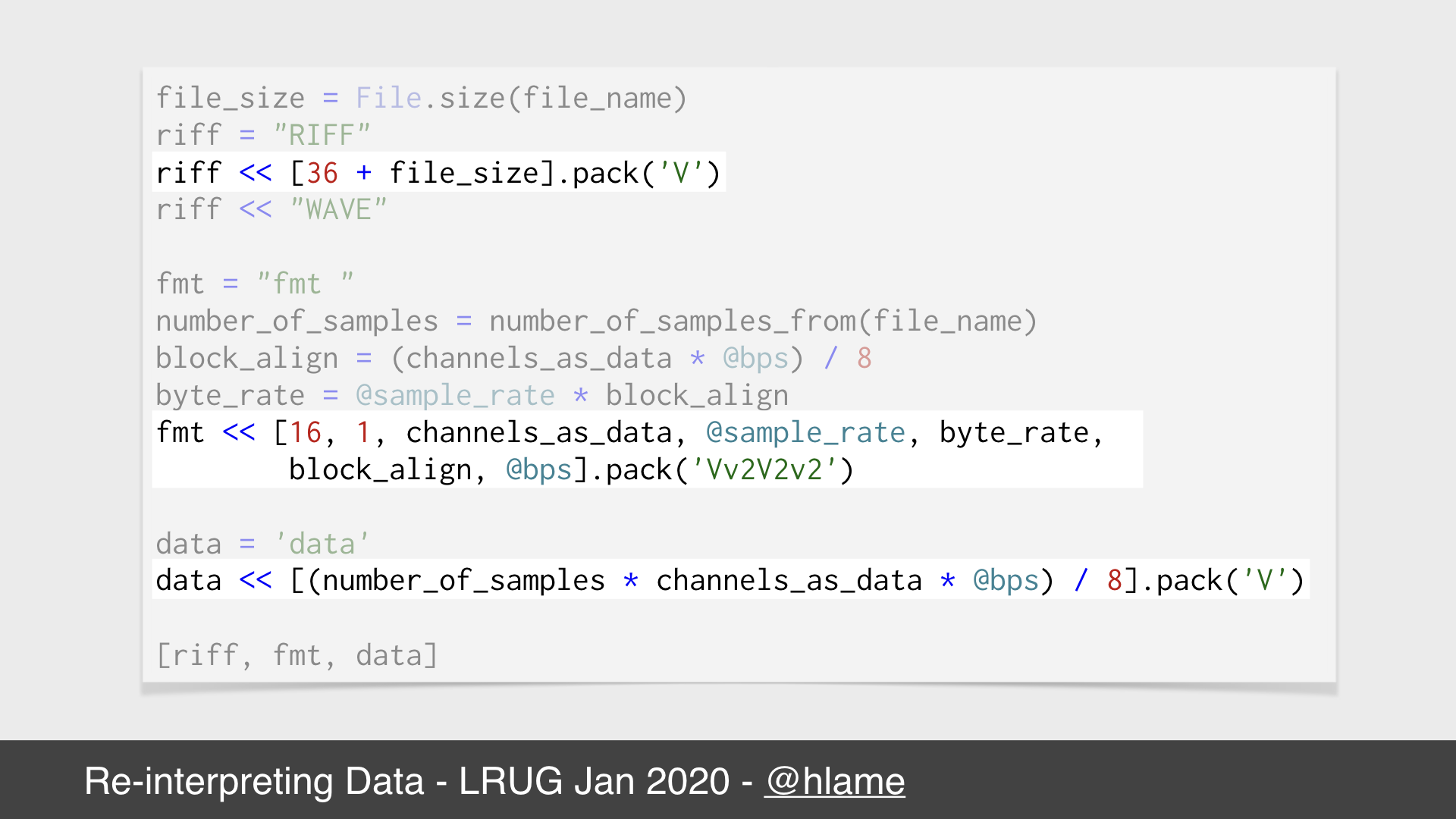
All that’s really interesting is the pack method. Called on an array of numbers, and passed a format string, pack will convert those integers into bytes according to the format string. E.g. you can say represent this number as a 4 byte number, or a 4 byte big endian number, or a 2 byte signed integer.
What a WAV file cares about is that some of the header is a 4 byte number, some is a 2 byte number, etc…. That’s what the pack statements here are, V for 4 byte big-endian, v for 2 byte big-endian.
The format string also takes numbers meaning, repeat the previous character this number of times. So to get four 4 byte big-endian numbers you can say VVVV or V4.
And, that’s basically all there is to it. So lets try it out.
Demo time: WAV (pt. 1)
So, let’s see what that sounds like shall we?
First we require the library, “stegosaurus”. Then we get a “waves” obejct from it - we can use this to make WAV files. Finally we call “make_from” and give it the path to a file.
We’ll use the README file that ships with this repo. Then in a separate shell we can run quicklook via qlmanage -p on the generated file to hear what it sounds like:
The stegosaurus README as a WAV file. Actually it’s an M4A version of the WAV to respect your download speeds, but you can click to download the WAV file if you really want it.
Yes, well, cough and you’ll miss it. The problem is, even at the lowest settings for how we encode a WAV file, there’s just not a lot of data in our README file to listen to. Can we try something else?
Demo time: WAV (pt. 2)
Ruby comes with a module called RbConfig that, among other things, includes a ruby method that returns the path to the currently running ruby interpreter. Let’s listen to that!
As before, we pass the path into the make_from method and then quicklook at the result in another terminal to hear what it sounds like:
The ruby 2.6.5 interpreter as a WAV file. Again, it’s an M4A version instead of the WAV for download brevity. The raw WAV is here though if you prefer the warmth of the original.
Sounds pretty good yeah?1 It’s nearly 3 minutes long, so we can skip around in the file to listen to different parts of the interpreter and get different sounds. I think I could probably give up my day job and become a DJ with this banging glitchy noise-core.
What about visuals?

The eagle eyed would have spotted the last slide said “WAV” demo, not just demo2.
There are other file formats that we can pull the same trick with. More or less.
If we can listen to our files as WAVs, what if we could look at them too?
The BMP file specification

We used WAV for audio, and there’s a similarly simple format for images too: BMP (or windows bitmaps). These are essentially the same kind of thing: a header that describes how to interpret the data as pixels and then the 1s and 0s that make up the pixels. So we should be able to do the same as we did with WAV files to let us see our files instead of hear them. We calculate the header based on some choices we make (e.g. colour depth expressed as bits per pixel) and then copy the raw data from our source file.
There are some gotchas though that mean we can’t just calculate the header and prepend it directly to our source file and expect it to work:
- Depending on the coulour-depth we use, we might need to add some bytes to make sure we have complete pixels.
- Images are rectangular, so we might need to add some pixels to make sure we have enough to make a rectangle.
- A quirk of the BMP format is that all rows of pixels have to be multiples of 4-bytes, so we might need to pad each row if our colour depth, or image size means a row wouldn’t be a multiple of 4 bytes otherwise.
In all these cases we add pad bytes set to 0x0. Now we’ll explore what each of these types of padding really means.
Data padding: pixels

First up, pixel padding.
One choice we make in the header is how many bits do we use per pixel to describe the colour of that pixel. A good choice is 24-bits, because it simplifies the file format. This means we need 8-bits (1 byte) for red, 8-bits (1 byte) for green and 8-bits (1 byte) for blue, giving us 24-bits or 3-bytes per pixel. The obvious problem here is what happens if our source file size is not a multiple of 3-bytes?
We pad the file, to add 0, 1 or 2 bytes to make sure we have exactly enough bytes to represent a whole number of pixels. E.g. a 100 byte file gets 2 bytes added to give us 102 bytes, or 34 pixels.
Data padding: width x height

Next up we have the width and heigh padding. e.g. making sure we can turn the number of pixels into a rectangular figure.
First we need to work out what kind of rectangle we can make with the pixels we have. The simplest rectangle is a square, and we can work that out quickly by taking the square root of the pixels we have. In this case we have 34 pixels which gives us ~5.831. We can’t have 0.831th of a row, so we round that up to get 6. This tells us we can create an image that is 6 high by 6 wide, which is 36 (6²) pixels in total.
Now we can subtract the number of pixels we have, 34, from the number of pixels we need, 36, to find out how many padding pixels we need to give us a square image, in this case 2. Of course, that needs to be converted to bytes and for our 24-bit colour depth at 3 bytes per pixel this means 6 more padding bytes for these padding pixels.
Data padding: scan lines

Finally, we have to deal with what the BMP specification calls “scan line padding”.
The specification says that each row of pixels in an image is called a “scan line” and each of these must be written in multiples of four bytes. That is, if we have 8-bit colour depth and a 3 pixel wide image, we need to add a single padding byte to the end of each row.
In our case we have 24-bit colour (3 bytes) representing 6 pixels in each scan line. As this is 18 bytes which is not a multiple of four, we need to pad each row to the next multiple of four, which is 20. This means adding 2 bytes per scan line, which is 12 more padding bytes.
Data padding: total

Ok, so to wrap it up we have chosen 24-bit (3 byte) colour depth for our image, and we have a 100 byte source file. This means adding:
2padding bytes to give us complete pixels6padding bytes to give us a square image12padding bytes to give us scan lines that are multiples of four bytes
Our 100 byte source file just became 120 bytes of pixel data in our BMP file.
So, how do we add these padding bytes?
Adding the pixel padding is easy, once we’ve used all the data in the source file, we then output the pixel padding bytes to complete the last pixel. We can do the same for the square padding bytes, once we’ve written the last pixel we can add all the empty pixels we need to complete the square image. However, the scan line padding bytes are more awkward.
We could just write them all at the end too, but this would mean “wasting” some of the source data bytes as scan line padding bytes, instead of using them as pixel bytes, so we want to interleave the pixel bytes from the source file with the scan line padding bytes.
Data padding in ruby #1
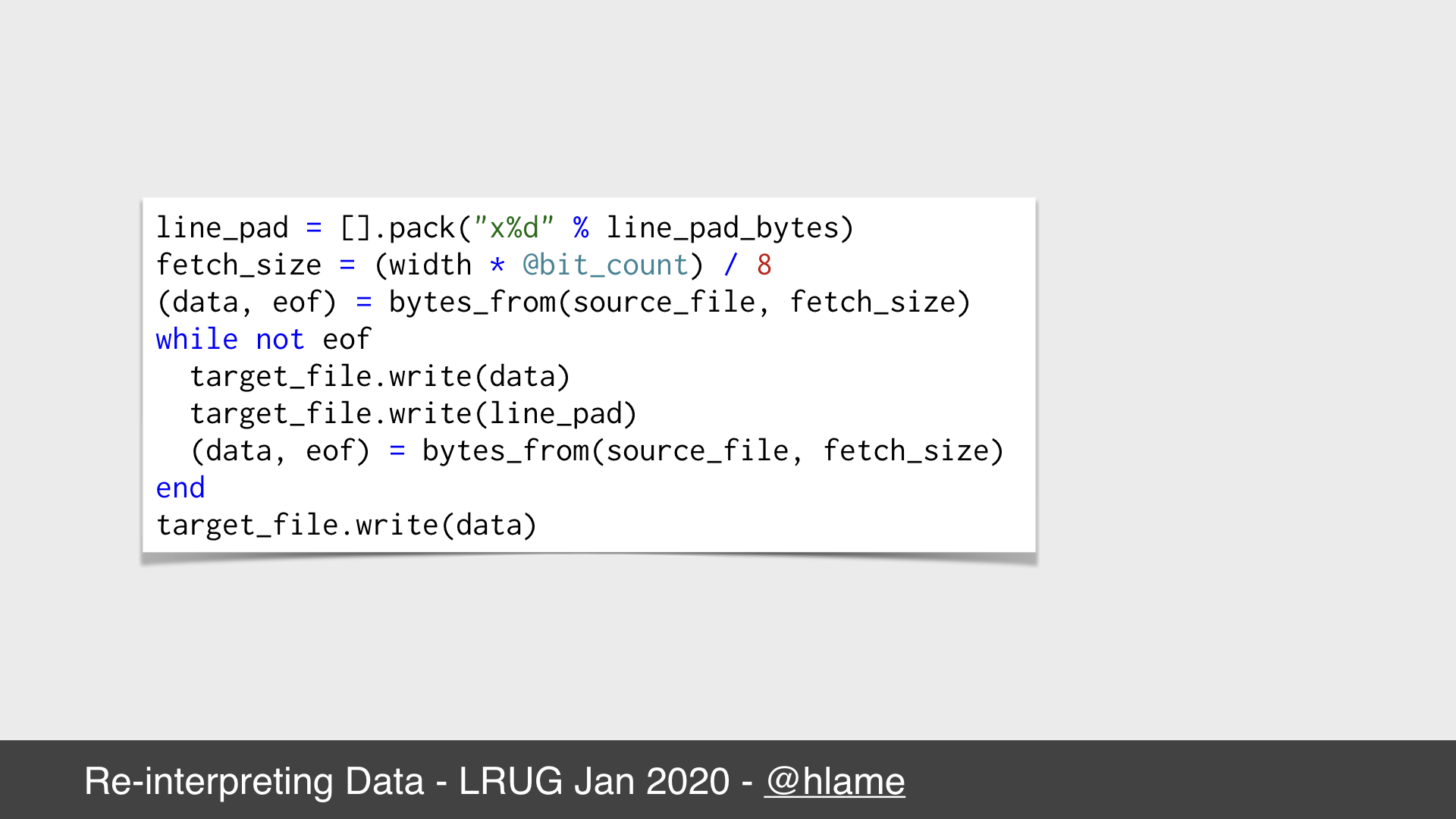
Here’s a snippet of code for doing that. As each line needs the same line padding we can calculate those bytes once at the start using our old friend pack (hello pack!). An interesting property of the pack method is that if your format string includes x it generates a null byte, regardless of the array contents in that position. This means you can call it on an empty array to get as many null bytes as you want. So for our 100 byte file, we’d call [].pack('x2') to get the string "\x00\x00" for 2 null bytes.
Then we extract exactly enough bytes for a full row of pixels from the source file (in our case 18 bytes) using bytes_from, a method that returns the bytes we need and an EOF flag if we’ve exhausted the file. Then we write those bytes plus the line padding bytes and loop until the file is exhausted.
Data padding in ruby #2
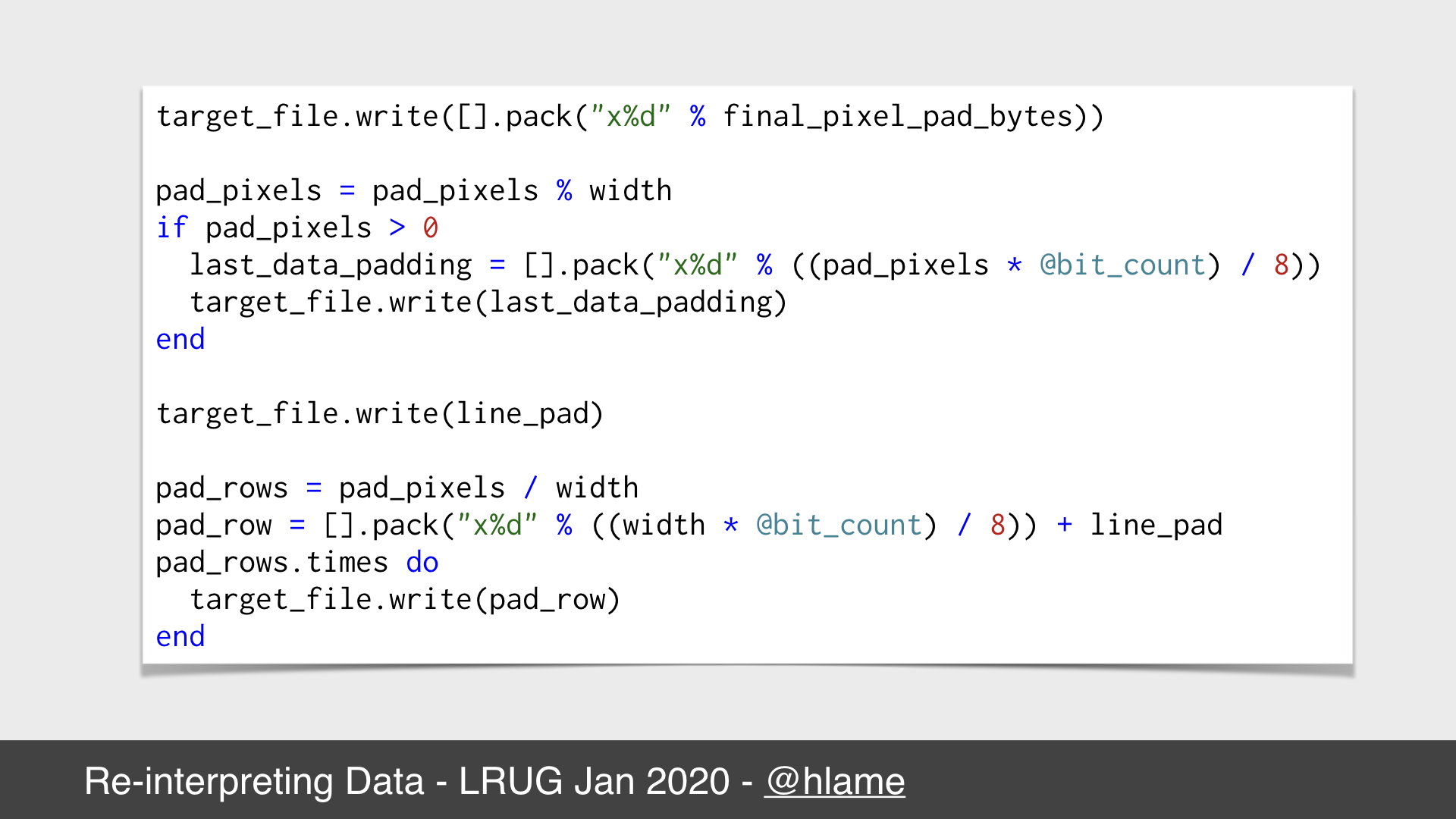
At the end of the code in the last slide we had a potentially incomplete scan line:
- We’re missing the padding bytes to make sure we complete the last pixel we made from the data at the end of the file.
- We’re missing the padding pixels we need to make sure the image is rectangular.
Of course, all of those pixels need to be added as complete scan lines too. It’s also possible that the padding pixels are more than a single scan line, so we need to cater for that when we write those bytes.
For our 100 byte file, each row is 6 pixels, which means 18 bytes. We can write 5 complete rows, consuming 90 bytes, but then we only have 10 bytes for our last row, which isn’t complete. To finish this row we have to:
- Write
"\x00\x00"as thefinal_pixel_pad_bytesto complete the last pixel because10pixels is3.333pixels so we need2bytes to complete that last pixel. This gives us12bytes. - Write
"\x00\x00\x00\x00\x00\x000"as thelast_data_paddingto complete the pixel data for the last row constructed from the file because12bytes is only4pixels so we need those extra6bytes to give us2extra pixels to make our6pixel row. This gives us18bytes. - Write
"\x00\x00"as theline_padto complete the final scan line because18bytes isn’t a factor of4so we need to add2bytes to get us to20which is a factor of4.
In this case, all our pad_pixels are added to the last scan line that contains bytes from the data file. It’s possible we need to add them as a complete scan line of their own, or split them across both the last data scan line, and a final padding scan line.
All this is annoying, but not particularly hard. It is a stark contrast to the WAV file where we could just read the size of the source file to generate the header and then prepend that onto the raw 1s and 0s of the source file with no manipulation.
Demo time: BMP (pt. 1)
Demo time!
As before, we require the library, and this time we get a bumps object as this is what makes BMP files. Then we pass it the README file again, and run quicklook on it to see what it looks like:

The stegosaurus README file, as a bitmap, albeit scaled up somewhat. Click through for actual size.
Not very interesting is it? As with the WAV file version of the readme, it’s small and not very interesting. It’s just some noise really. Let’s try something more interesting.
Demo time: BMP (pt. 2)
That’s more like it - we pass the ruby interpreter using RbConfig.ruby like we did for the WAV file demo and get to see what the ruby interpreter looks like:

The ruby 2.6.5 interpreter as a bitmap, albeit scaled down somewhat. Click through for actual size. I tried saving as a JPEG or PNG to get a smaller file, but it didn’t really help, sorry).
{kind=link}
With the WAV file, had we listened to the entire “song” we’d have noticed the different parts that we can see clearly in this image version. There’s some structure to the file, for example, the start of the interpreter is all pinky-red, as you might expect for the ruby language, then there’s a dark bit (probably all the stuff shamefully inherited from perl) and the majority of the interpreter is this noisy green stuff, which I’m sure you all recognise. Maybe it’s the error handling?
Other audio?

So, now we’ve looked at some files it’s a little clearer why the WAV demo was so painful to listen to; the 1s and 0s in most source files are pretty chaotic. Wouldn’t it be nice to hear something more melodic?
As it turns out, yes we can, using MIDI.
The MIDI file specification

In a WAV file, the data is a digital representation of a sound wave; it’s a recording of a sound turned into 1s and 0s using maths. MIDI however is more like a digital representation of sheet music; it tells a player what instrument to use, what note to play, for how long, how loudly, etc…
Happily the file specification says that MIDI files are not so different to what we’ve already seen with WAV and BMP: there’s a header followed by some data. Unfortunately the data part has more rules and structure than BMP so we have to manipulate our source bytes even more.
MIDI Events

The data part of a MIDI file is made up of a stream of MIDI Events. You can think of these like the notes on sheet music. Each event has three parts:
- delta time: this tells the MIDI player when to trigger this event. It’s a variable length value of between
1and4bytes. It’s the number quarter-note fractions to delay the event by, the exact meaning of which in elapsed time depends on some header settings. - status: this tells the MIDI player what this event actually is. There are events to turn a note on, or turn a note off, or to say how much “aftertouch” to apply to a note, or other esoteric MIDI things. This is always
1byte. - event data: this provides any extra information that the event needs, based on the status. For example the “turn this note on” status needs to say which note and how fast. This part is usually
1or2bytes long, but sometimes0if the status has no extra data requirements.
There are lots of different events, but for this library I only care about the “turn this note on” and “turn this note off” events.
MIDI EVents: delta time

Delta time is stored as a variable length value of between 1 and 4 bytes. How this is implemented is that a single byte is split into two parts: 7 bits are used to store the value, and the remaining 1 bit is used to say if the next byte contains more data for the value or not.
0 means no more data, 1 means the next byte contains data. Values less than 128 can be stored in 1 byte, values more than 128 are stored in multiple bytes. In theory we could allow for infinitely large values as we can keep setting the “more” bit to 1, but in practice, the MIDI spec says 4 bytes is the maximum. This gives us 24 bits to store a value, allowing us to store values from 0 to 16,777,215. This should be enough.
MIDI Events: status + data

In MIDI all status bytes are values greater than 128, and all data bytes are values less than 128. Meaning we use 1 bit of the byte to tell us if the byte contains a status or some data.
We’re interested in the “turn this note on” and “turn this note off” statuses which are represented as follows:
1000xxxxfor “turn this note on”1001xxxxfor “turn this note off”
The remaining 4 bits of the status byte contain the channel number for the note. MIDI allows a track to have up to 16 channels and this part of the status byte is used to say which channel to run the event on.
The value of the status byte tells us how many data bytes we need. Our note events both take 2 bytes of data; one for the key, and one for the velocity.
The problem here is that it’s very unlikely we’re going to have the raw bytes in our source file arranged in the proper sequence so that all our bytes with values of 128 or more are followed by exactly 2 bytes of values less than 128. How can we manipulate the source data to make valid MIDI files?
MIDI Events: solution

Our solution is to deal with the bits within the source file, not the bytes. We need 27 bits of data from the source file to make one MIDI event:
8bits can be used to extract the delta time - using variable length encoding of the value this’ll be turned into either1or2bytes.1bit to decide between a “turn this note on” and “turn this note off” status event.4bits to say which channel the status event should run on.7bits to encode as the key data byte for the status event.7bits to encode as the velocity data byte for the state event.
This way we can use all the data from our source file and be sure that it’s going to be arranged correctly for making valid MIDI data.
MIDI Events in ruby
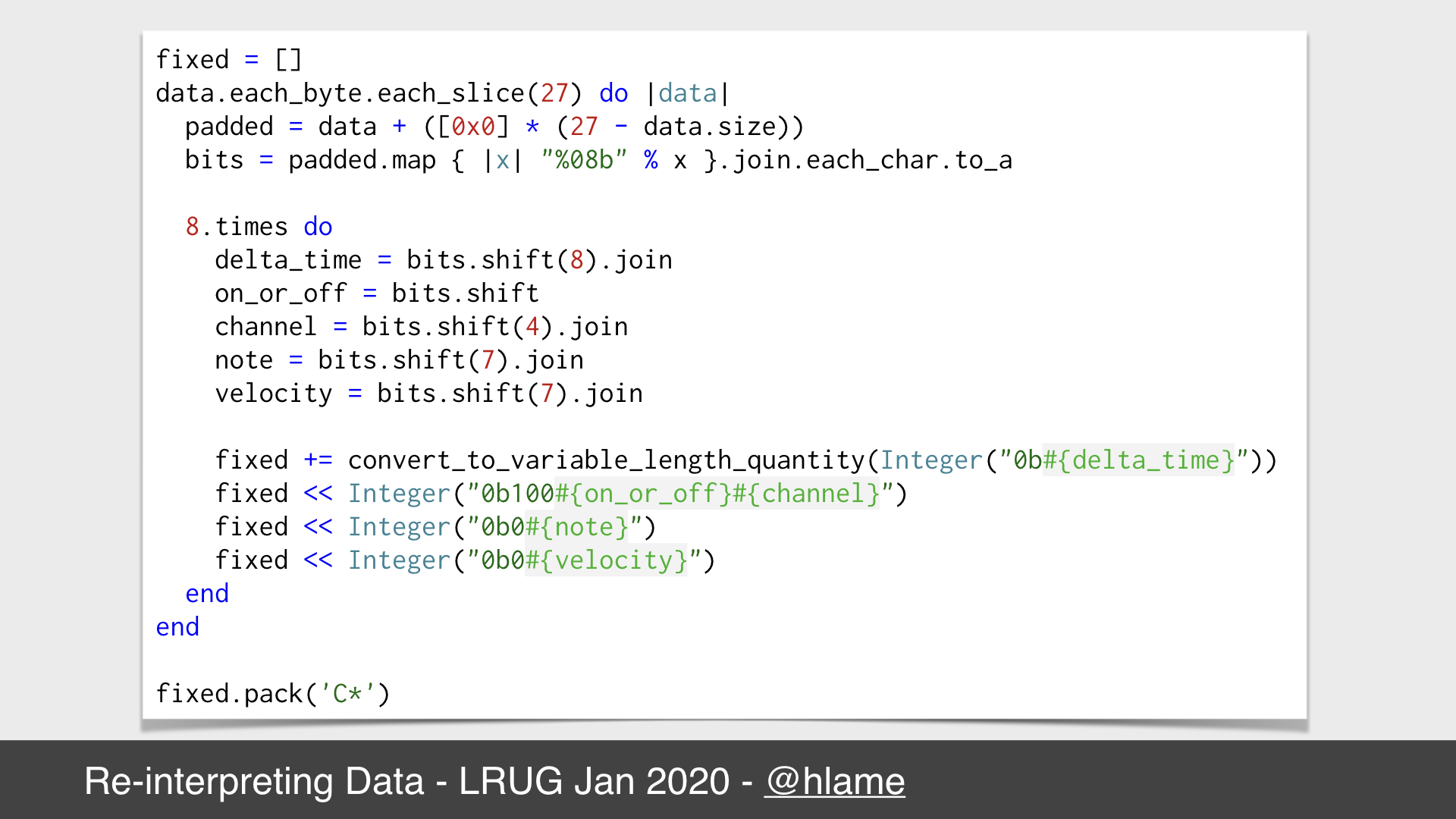
Here’s the code to do just that. First we read 27 bytes from the source file and we pad it with zeros if there aren’t 27 bytes available (e.g. at the end of the file). We read 27 bytes because there’s no smaller common factor of 27 (the number of bits we want per event) and 8 (the smallest number of bits we can read at a time). This means we have 216 bits (27 × 8) which gives us enough bits for 8 (216 ÷ 27) events.
We turn those bytes into their binary representation and turn this into an array which gives us 216 1s and 0s. This allows us to loop 8 times to pull out chunks of 27 bits as we outlined above:
8bits for the delta time,1bit for the on / off flag,4bits for the MIDI channel,7bits for the key,7bits for the velocity.
Finally, we write all those bits to our new file with the necessary extra bits around them to make the raw data into valid MIDI delta times, status events and data bytes. So now we have unsophisticated, but valid, MIDI data generated from arbitrary data.
Demo time: MIDI (pt. 1)
As expected we require stegosaurus and get our object for making thingse, this time a midriffs, and then pass it the README file. We can’t use quicklook this time around, because macos doesn’t have default support for MIDI files. It’s actually a bit of a faff, but there’s a program called timidity that you can install via brew and this’ll play the file. So we pass it to that to hear what it sounds like:
The stegosaurus README file, as a MIDI file. Actually this is a M4A recording of the MIDI played via timidity because browsers no longer support direct MIDI playing. But you can still click to download the MIDI file if you want it.
So it’s longer than the WAV version at 6 seconds rather than almost none. But this is what you might expect as MIDI is a set of notes to be played so we get more sound with less data. Let’s see what even more data sounds like.
Demo time: MIDI (pt. 2)
Once again, we use the currently running ruby interpreter as the input file and this time we get a MIDI file as our reward. So lets give it a listen:
The ruby 2.6.5 interpreter as a MIDI file - (once again this is a M4A version of the MIDI played via timidity beceause <%= browsers %>, or you can click to download the MIDI file if you want it.
Again, it’s longer than the WAV version at just over an hour4. Alas it still sounds like a piano being pushed down the stairs, but, I dunno, there’s a chaotic charm to it. Why not leave it on in the background as some focused coding music?
I still think there’s scope for me to have a late-stage career change and become an esoteric DJ and avant-noise club nights.
Why ruby?

So, why ruby though?
We don’t normally do this kind of thing in a language like ruby; byte-level and even bit-level manipulation is pretty unweildy, shouldn’t you use C?
Probably, but ruby is the language I know best, and I was able to get fast feedback by using ruby. That feels important to me when playing about with these kinds of toys.
Source code

All the code lives here. I chose this name because I thought of this as a simple steganography tool to allow you to could hide data inside other formats. Except as BMP and MIDI both inject bits and bytes into the source data, you’d need a reconstruction routine and I never wrote that because … well, this was for fun, not something serious.
Or maybe I chose the name because I’m a man-baby who still thinks dinosaurs are cool?
Who could say?
Thanks for listening
Thanks for listening!
Bye!